The Rainforest QA 2024 survey of 625 software developers and engineering leaders found that 55% of teams using open-source frameworks spend more than 20 hours per week creating and maintaining automated tests. The World Quality Report series, based on interviews with 1,750 CxOs and senior technology professionals, found maintenance can consume up to 50% of the overall test automation budget.
Self-healing tests promise to fix this. But a Pulse Opinion Research survey found only 4% of IT leaders said their test automation AI features worked "Very Well." And industry reports suggest up to 41% of teams abandon these tools within the first year.
I've spent a lot of time evaluating these tools and talking to teams who've tried them. So what is actually going on? This article breaks down the approaches, the tools, the real limitations, and what to actually expect.
Locators Are Only 28% of the Problem
I think this is the most important data point that self-healing marketing ignores: selector failures account for roughly 28% of real-world test failures.
QA Wolf published a breakdown of what actually causes test failures in production suites:
| Failure Type | % of Failures | Can Self-Healing Fix It? |
|---|---|---|
| Timing / async issues | ~30% | Only indirectly |
| Broken selectors | ~28% | Yes |
| Test data problems | ~14% | No |
| Visual assertion diffs | ~10% | No |
| Interaction changes (UI reorganization) | ~10% | Sometimes |
| Runtime errors (app crashes, env issues) | ~8% | No |
If your self-healing tool only fixes locators — and most do — it addresses less than a third of your maintenance burden. The other 72% requires fundamentally different solutions: better wait strategies, test data management, environment stability, and smarter assertions.
This does not mean self-healing is worthless — I've seen it save hours on the tedious work of manually updating selectors. But calibrate your expectations accordingly.
The Six Approaches to Self-Healing
Not all self-healing is the same. I tried to categorize the main approaches, and the implementations vary significantly in how they work and what they can actually fix.
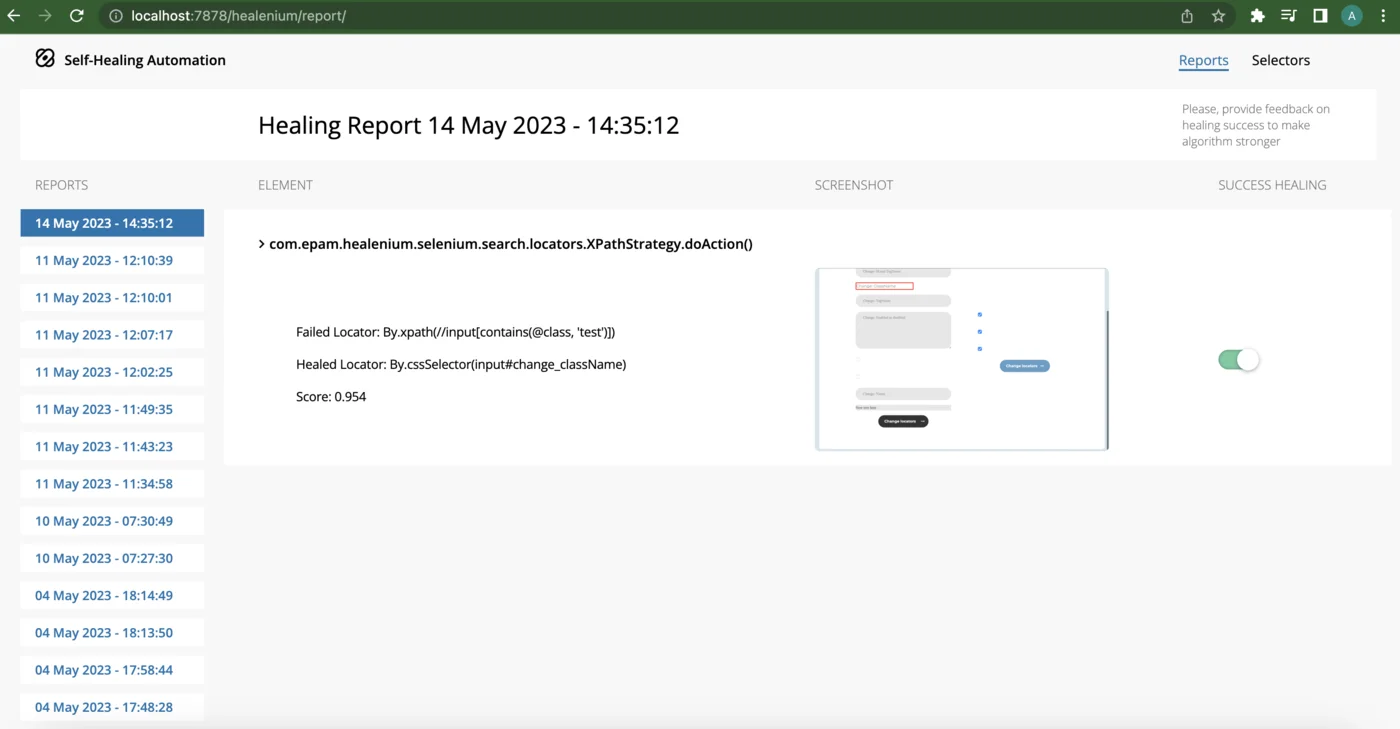
1. DOM Tree Comparison (Healenium)
Healenium is the most widely adopted open-source option, built by EPAM. It wraps Selenium WebDriver and intercepts findElement() calls.
How it works: When an element is found successfully, Healenium stores the full DOM tree path and element attributes in PostgreSQL. When a NoSuchElementException fires, it retrieves the stored DOM tree, compares it to the current page DOM using the Longest Common Subsequence (LCS) algorithm, and generates ranked candidate locators with confidence scores.
Strengths: Open source, works with any Selenium project (add it as a JAR dependency), stores healing history for audit.
Limitations: Requires running Docker containers (HLM-Backend + PostgreSQL). Only works with Selenium — no Playwright support. I found the LCS algorithm to be purely structural, not semantic — it cannot understand what an element does, only where it was in the tree.
2. Multi-Attribute Fingerprinting (mabl)
mabl captures over 35 unique attributes per UI element during test recording. During execution, it scores all candidate elements against this fingerprint.
How it works: When the primary locator fails, mabl evaluates every element on the page against the stored attribute model. If standard fingerprinting fails, it falls back to generative AI for semantic matching — understanding what an element "means" rather than just matching strings.
This two-stage approach (attribute matching first, GenAI fallback second) is, in my opinion, the most sophisticated healing available in a commercial tool as of early 2026.
3. Two-Tier Healing: Classic + AI (Katalon Studio 11)
Katalon has offered self-healing for years through ordered fallback chains — when the default locator fails, it tries alternatives in a user-defined order: XPath, CSS, Attributes, Image-based. This classic approach is deterministic and fast, but limited to known locator types.
What changed in January 2026: Katalon Studio 11 added a second tier of AI-powered healing that activates when the classic fallback chain fails. This tier uses an LLM to analyze multiple inputs — page source code, accessibility tree, full-page screenshots, and element screenshots — to intelligently locate the changed element.
The two tiers work in cascade:
- Classic self-healing tries alternative locator strategies first (fast, no AI cost)
- AI self-healing engages only when classic methods fail (slower, uses LLM tokens)
You configure which input sources the AI uses in Project Settings > Self-Healing. Using screenshots gives more accurate results but costs more in LLM processing. Accessibility tree analysis is cheaper and often sufficient. By default it uses the model configured in Katalon's AI preferences, but you can override with your own OpenAI API key.
After execution, the Self-healing Insights tab shows what was healed (by which tier) and lets you approve or reject changes.
4. ML-Based Smart Locators (Testim)
Testim (now part of Tricentis) takes a different approach from both classic and LLM-based healing. Its ML-based "Smart Locators" analyze thousands of attributes per element and rank their reliability. Instead of reacting to failure, Testim builds a robust locator model upfront that degrades gracefully.
Their 2025 update adds improved recovery mechanisms with conditional waits and dynamic retries based on real-time page behavior — addressing timing issues, not just locator changes.
5. Infrastructure-Level Healing (Applitools)
Instead of modifying your test code, you run your existing Selenium/WebDriver tests on Applitools' cloud infrastructure. The cloud intercepts failing locators and uses Visual AI to find the correct element. It also inserts implicit waits to handle timing issues.
The key distinction: Your test code stays unchanged. The healing happens in the execution layer. You change a few lines of setup configuration, and your existing tests gain self-healing. Named a Strong Performer in the Forrester Wave: Autonomous Testing Platforms, Q4 2025.
6. Post-Failure AI Analysis (Qate AI)
A newer approach that several tools are exploring (including Qate and some custom in-house solutions): instead of healing at runtime, the AI analyzes failures after the test run, with access to the full DOM diff and optionally the application source code.
How it works: When a test fails, an AI agent examines the failure context — error message, DOM changes, and if a repository is connected, the actual code that changed. It produces a suggested fix (updated selectors, modified steps, adjusted waits) that a human reviews before applying.
The key distinction from runtime healing: The test stays broken until a human approves the fix. This avoids the dangerous failure mode (see below) where a healed test silently passes when it should not. The downside is that it creates a review backlog.
The Dangerous Failure Mode
I believe the biggest risk of self-healing is not a test that fails — it is a test that passes when it should not.
A documented real-world case from the Ranorex blog: developers removed required field validation from a payment form. The self-healing algorithm "fixed" the tests by finding alternative elements. The tests passed. But they were no longer validating the payment process correctly. The missing validation went undetected until customers experienced payment failures in production.
This is why the "heal at runtime" vs. "suggest fixes for review" distinction matters:
Runtime healing (Healenium, mabl, Applitools):
- Tests do not fail in CI — pipeline stays green
- No human intervention needed for simple changes
- Risk: masks real bugs, erodes trust in test results, 2-3x slower execution
Suggest-and-review (Katalon Insights, post-failure analysis tools):
- Tests fail until a human approves the fix
- Human validates that the healed test still tests the right thing
- Risk: creates a review backlog if the application changes frequently
From what I've seen, the industry is converging on a hybrid approach: heal at runtime to complete the test run, but clearly flag healed tests in reports and queue them for human review before the fix becomes permanent. If your tool does not show you what it healed, I'd be very cautious.
The Honest Numbers
A Ranorex analysis of enterprise implementations found:
- 23% higher false positive rates compared to traditional test maintenance
- 31% more time spent on test debugging due to AI-introduced inconsistencies
- 60% of teams disable AI features within three months of enabling them
- Tests run 2-3x slower when self-healing is enabled
On the positive side, teams that successfully implement self-healing report significant reductions in selector maintenance effort. And mabl reports that their GenAI-enhanced healing handles cases that pure attribute matching misses.
I think the gap between marketing claims and practitioner experience is real but narrowing. The tools have improved significantly from 2024 to 2026 — particularly with the addition of generative AI fallbacks and better failure classification.
What to Actually Evaluate
When assessing self-healing capabilities, these are the questions I always ask:
-
Does it only fix locators, or does it handle workflow changes? Locator healing is table stakes. Flow-level adaptation — handling new intermediate steps, reorganized navigation, changed form structures — is where real value lies.
-
Does it distinguish bugs from test issues? If a button is intentionally removed, the test should fail. A tool that heals around the absence is hiding a regression. Look for tools that differentiate between "the application changed and should not have" and "the test needs updating."
-
Can you see what changed? Transparency is non-negotiable. You need a clear report of what was healed, the confidence level, and the ability to approve or reject. In regulated industries, unexplained test behavior is a compliance problem.
-
Does it integrate with your codebase? Healing is more accurate when the AI can read the source code that changed. Some tools (Qate, and increasingly others) connect to your repository to investigate why the DOM changed before deciding how to fix the test.
-
What is the performance impact? If self-healing doubles your test execution time, the time saved on maintenance may be eaten by slower CI pipelines.
The Bottom Line
Self-healing is a real capability that addresses a real problem. But it is not magic, and I think the marketing from most vendors significantly oversells it.
The most effective approach depends on your situation:
- Small suite, stable UI, strong engineering team: You probably do not need self-healing. Playwright's smart locators (
getByRole,getByText,getByTestId) and good test architecture will serve you well. - Large suite, frequent UI changes, mixed-skill team: Self-healing pays for itself quickly, especially if your tool handles more than just locator healing.
- Regulated industry: Choose a suggest-and-review approach with full audit trails. Runtime healing without human oversight is a compliance risk.
I'm convinced the tools that will win are the ones that are honest about what they can and cannot fix, that keep humans in the loop for judgment calls, and that address the full 100% of test failures — not just the 28% that are locator problems.